Linking to GEOS 3.9.1, GDAL 3.3.2, PROJ 7.2.1; sf_use_s2() is TRUE
# --- first, figure out the # of homicides and burglaries by block group# load crime datac2018 <-st_read("H:/pppa_data_viz/2019/tutorial_data/lecture05/Crime_Incidents_in_2018/Crime_Incidents_in_2018.shp")
Reading layer `Crime_Incidents_in_2018' from data source
`H:\pppa_data_viz\2019\tutorial_data\lecture05\Crime_Incidents_in_2018\Crime_Incidents_in_2018.shp'
using driver `ESRI Shapefile'
Simple feature collection with 33645 features and 23 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -77.11232 ymin: 38.81467 xmax: -76.91002 ymax: 38.9937
Geodetic CRS: WGS 84
# make smaller dataframe -- just homicides and burglariesvc2018 <- c2018[which(c2018$OFFENSE =="HOMICIDE"| c2018$OFFENSE =="BURGLARY"),]# load block group mapbg2010 <-st_read("H:/pppa_data_viz/2019/tutorial_data/lecture05/Census_Block_Groups__2010/Census_Block_Groups__2010.shp")
Reading layer `Census_Block_Groups__2010' from data source
`H:\pppa_data_viz\2019\tutorial_data\lecture05\Census_Block_Groups__2010\Census_Block_Groups__2010.shp'
using driver `ESRI Shapefile'
Simple feature collection with 450 features and 54 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -77.11976 ymin: 38.79165 xmax: -76.9094 ymax: 38.99581
Geodetic CRS: WGS 84
`summarise()` has grouped output by 'TRACT', 'BLKGRP'. You can override using
the `.groups` argument.
# make a no-geography version of dataframe with all block groups for faster processingbg2010.small.noshp <- bg2010.smallst_geometry(bg2010.small.noshp) <-NULL# --- finally calculate # of missings# -- method 1: make two separate dataframes for homicides and burglaries# -- then merge into all-block group dataframe# make separate dfs# homicides onlyhom <- cbgs[which(cbgs$OFFENSE =="HOMICIDE"),]# burglaries onlyburglary <- cbgs[which(cbgs$OFFENSE =="BURGLARY"),]# merge homicide data with all block groupsall.bgs <-merge(x = hom,y = bg2010.small.noshp,by =c("TRACT","BLKGRP"),all =TRUE)print("here we look at # of obs that have no homicide offense")
[1] "here we look at # of obs that have no homicide offense"
table(is.na(all.bgs$OFFENSE), useNA ="always")
FALSE TRUE <NA>
97 353 0
# merge burglary data with all block groupsall.bgs.b <-merge(x = burglary,y = bg2010.small.noshp,by =c("TRACT","BLKGRP"),all =TRUE)print("here we look at # of obs that have no burglary offense")
[1] "here we look at # of obs that have no burglary offense"
table(is.na(all.bgs.b$OFFENSE), useNA ="always")
FALSE TRUE <NA>
381 69 0
# -- method 2: make homicides and burglaries dataframe wide, then merge in# make the thing widewider <-pivot_wider(data = cbgs,names_from = OFFENSE,values_from = incidents)print(head(wider))
# A tibble: 6 × 4
# Groups: TRACT, BLKGRP [6]
TRACT BLKGRP BURGLARY HOMICIDE
<chr> <chr> <int> <int>
1 000100 2 1 NA
2 000100 3 1 NA
3 000100 4 5 NA
4 000201 1 3 NA
5 000202 1 2 NA
6 000202 2 2 NA
# then merge the wide thing with all the block groupsall.bgs2 <-merge(x = wider,y = bg2010.small.noshp,by =c("TRACT","BLKGRP"),all =TRUE)print(head(all.bgs))
TRACT BLKGRP OFFENSE incidents
1 000100 1 <NA> NA
2 000100 2 <NA> NA
3 000100 3 <NA> NA
4 000100 4 <NA> NA
5 000201 1 <NA> NA
6 000202 1 <NA> NA
# now we can count NAs by typefinal.table <-group_by(.data = all.bgs2)final.table <-summarize(.data = final.table,total.block.groups =n(),has.no.burglary =sum(is.na(BURGLARY)),has.no.homicide =sum(is.na(HOMICIDE)))print("this is the final output from doing things with pivot_wider")
[1] "this is the final output from doing things with pivot_wider"
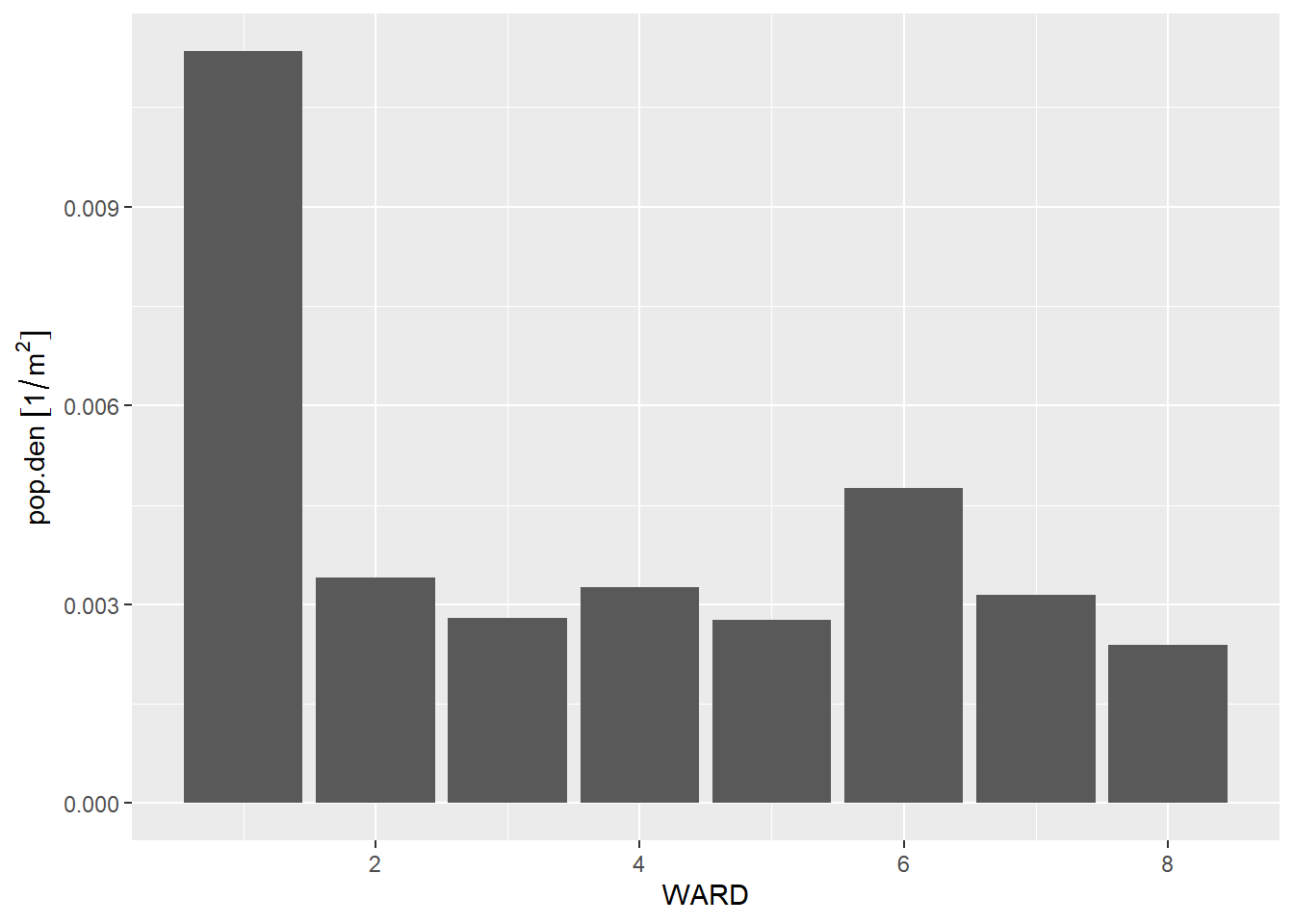
Make a bar chart that shows the population density (people / area) by ward. You may wish to use st_area() to find the area of each ward. Population is already in the ward dataframe.
Answer:
# load library units so command doesnt get mad at melibrary(units)
udunits database from C:/Users/lbrooks/AppData/Local/R/win-library/4.2/units/share/udunits/udunits2.xml
# load dc ward shapefiledc.wards <-st_read("H:/pppa_data_viz/2019/tutorial_data/lecture05/Ward_from_2012/Ward_from_2012.shp")
Reading layer `Ward_from_2012' from data source
`H:\pppa_data_viz\2019\tutorial_data\lecture05\Ward_from_2012\Ward_from_2012.shp'
using driver `ESRI Shapefile'
Simple feature collection with 8 features and 82 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -77.1198 ymin: 38.79164 xmax: -76.90915 ymax: 38.99597
Geodetic CRS: WGS 84
# find the area of each warddc.wards$area <-st_area(dc.wards)# find the population densitydc.wards$pop.den <- dc.wards$POP_2010 / dc.wards$area# plot the population densitydenso <-ggplot() +geom_col(data = dc.wards,mapping =aes(x = WARD, y = pop.den))print(denso)
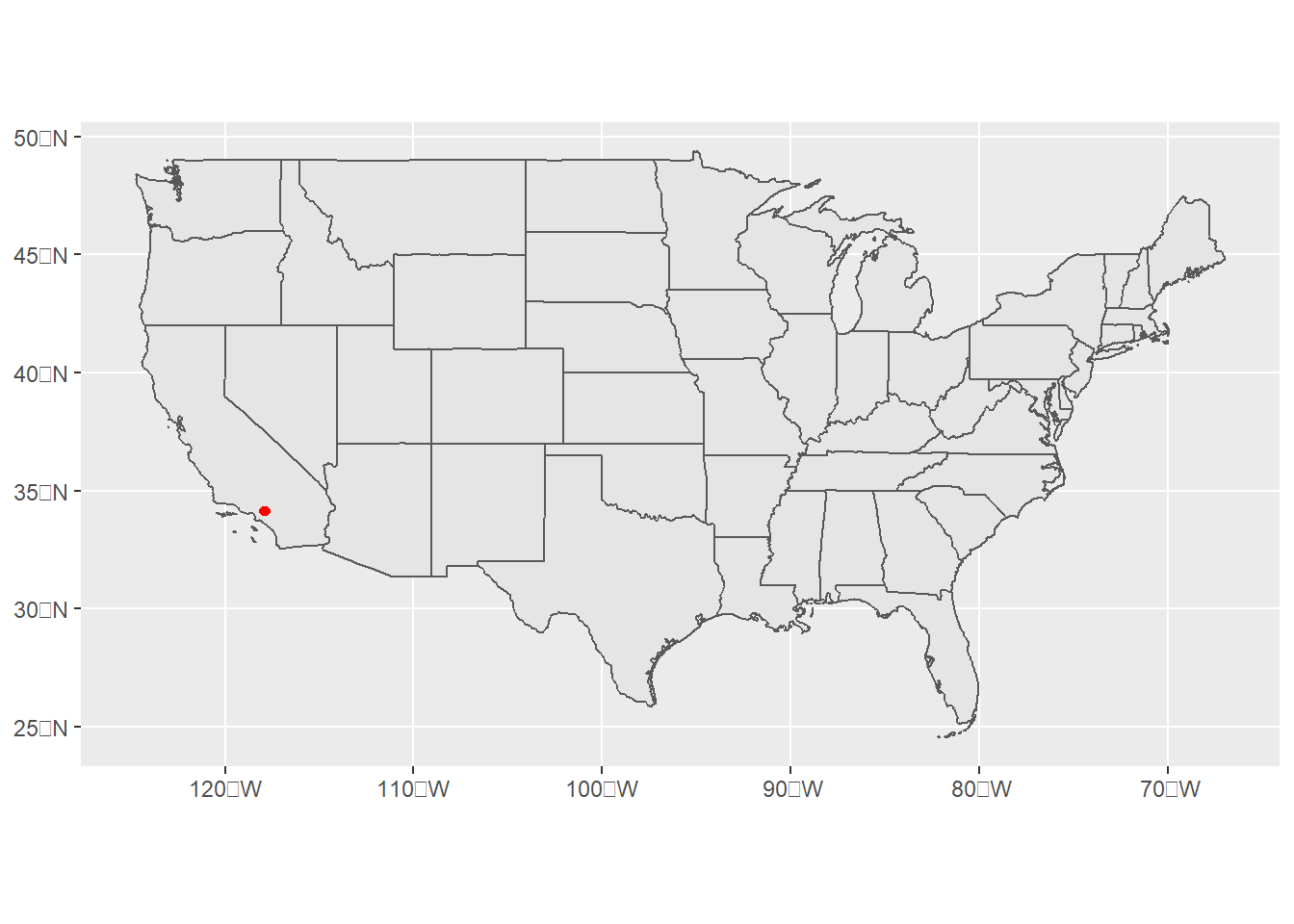
Get two other maps (in shapefile format) not used in this tutorial. Make one ggplot with both of them, and fix the options so that it looks decent.
Answer:
I tried to plot the location of all US Costcos. But the Costco map I found was terrible! It had only two locations. But I plotted nonetheless.
# plotting costco locations in the us# found costco locations here# https://www.arcgis.com/home/item.html?id=fea1d6b4a9a04e688b8e61a716150381costcomap <-st_read("H:/pppa_data_viz/2023/tutorials/answer_programs/tutorial_05/Costco/Costco.shp")
Reading layer `Costco' from data source
`H:\pppa_data_viz\2023\tutorials\answer_programs\tutorial_05\Costco\Costco.shp'
using driver `ESRI Shapefile'
Simple feature collection with 2 features and 44 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -117.9282 ymin: 34.11354 xmax: -117.8284 ymax: 34.13357
Geodetic CRS: WGS 84
head(costcomap)
Simple feature collection with 2 features and 44 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -117.9282 ymin: 34.11354 xmax: -117.8284 ymax: 34.13357
Geodetic CRS: WGS 84
X_storefron address address_li
1 <NA> 1220 W Foothill Blvd <NA>
2 <NA> 520 N Lone Hill Ave <NA>
category
1 financial,auto rental,general merchandise ,fuel,grocery,travel,auto service,insurance,optometry,hearing,pharmacy,big box stores
2 financial,auto rental,general merchandise ,fuel,grocery,travel,auto service,insurance,optometry,hearing,pharmacy,big box stores
city country distributo email_addr fax_number
1 Azusa United States <NA> <NA> <NA>
2 San Dimas United States <NA> <NA> <NA>
geo_accura last_updat latitude list_id list_name
1 STREET_ADDRESS: ROOFTOP 2018-06-01 34.13357 129 Costco Wholesale Corp.
2 STREET_ADDRESS: ROOFTOP 2018-06-01 34.11354 129 Costco Wholesale Corp.
longitude opening_da
1 -117.9282 1-Oct-83
2 -117.8284 16-May-08
store_hour pharmacy
1 M-F 10:00am - 8:30pm Sat 9:30am - 6:00pm Sun 10:00am - 6:00pm TRUE
2 M-F 10:00am - 8:30pm Sat. 9:30am - 6:00pm Sun. 10:00am - 6:00pm TRUE
pharmacy_p pharmacy_h optical
1 (209) 725-5030 M-F 10:00am-7:00pm SAT 9:30am-6:00pm SUN CLOSED TRUE
2 (916) 789-1493 M-F 9:00am-7:00pm SAT 9:00am-6:00pm SUN CLOSED TRUE
hearing food_court gas tires country_co county parent_lis
1 TRUE TRUE TRUE TRUE US Los Angeles County <NA>
2 TRUE TRUE TRUE TRUE US Los Angeles County <NA>
parent_l_1 phone_numb regions sic_code source_url special_ho
1 <NA> (626) 812-7911 <NA> 5399 www.costco.com <NA>
2 <NA> (909) 962-5507 <NA> 5399 www.costco.com <NA>
special__1 state store_name store_numb store_type ali unformatte
1 <NA> CA Azusa 412 <NA> 129293089-005187 <NA>
2 <NA> CA San Dimas 1015 <NA> 129293276-003410 <NA>
unformat_1 website_ad zip_code geometry
1 6268127911 <NA> 91702-2819 POINT (-117.9282 34.13357)
2 9099625507 <NA> 91773-1725 POINT (-117.8284 34.11354)
dim(costcomap)
[1] 2 45
# get us mapusmap <-st_read("H:/maps/united_states/census2010/states/gz_2010_us_040_00_20m.shp")
Reading layer `gz_2010_us_040_00_20m' from data source
`H:\maps\united_states\census2010\states\gz_2010_us_040_00_20m.shp'
using driver `ESRI Shapefile'
Simple feature collection with 52 features and 5 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -179.1473 ymin: 17.88481 xmax: 179.7785 ymax: 71.35256
Geodetic CRS: NAD83
# omit AK, HI, PRusmap.cont <- usmap[which(!(usmap$STATE %in%c("02","15","72"))),]# put on top of us mapstates <-ggplot() +geom_sf(data = usmap.cont) +geom_sf(data = costcomap, color ="red")states